

When dealing with massive volumes of data, traditional real-time processing approaches may prove ineffective, leading to bottlenecks and performance issues. Here’s where batch processing comes to the rescue.
Batch processing involves processing data in chunks, making it an excellent choice for handling large datasets in a scheduled or periodic manner. In this blog, we will explore the concept of batch processing, its advantages, and how it can be implemented using code examples.
What is Batch Processing?
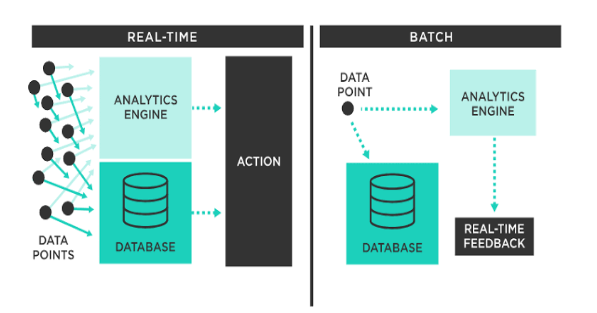
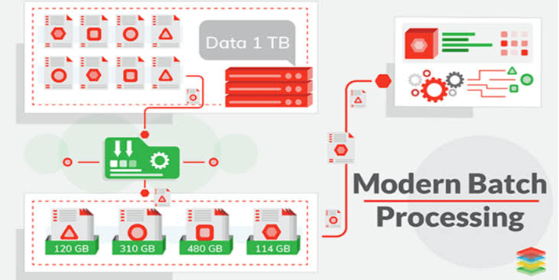
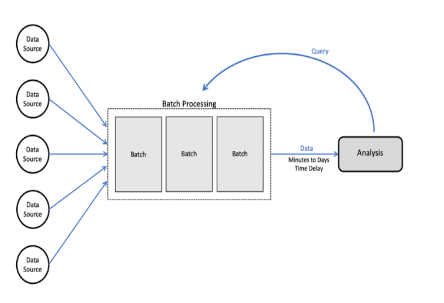
Batch processing is a data processing technique where data is collected, processed, and stored in batches, rather than being processed in real-time. It allows organizations to process vast amounts of data efficiently and cost-effectively. Batch processing involves three key steps: data collection, data processing, and data storage.
Data Collection
The first step in batch processing is data collection. This involves gathering and consolidating data from various sources into a centralized repository. The data is usually stored in files or databases, ready for further processing.
Batch processing is particularly well-suited for scenarios where data accumulates over time and can be processed in discrete chunks. For example, financial institutions often use batch processing to reconcile transactions at the end of the day or generate monthly reports based on accumulated data.
Data Processing
Once the data is collected, it is processed in batches. Unlike real-time processing, where data is processed immediately as it arrives, batch processing waits for a predetermined amount of data to accumulate before initiating the processing task. This approach enables optimizations and efficiencies during data processing.
Batch processing is designed to handle large volumes of data efficiently, allowing organizations to process data in parallel and take advantage of distributed computing resources. This scalability is critical when dealing with big data workloads that surpass the processing capabilities of a single machine.
Data Storage
After processing, the results are stored back into the database or files. This transformed data is then used for reporting, analysis, or as input for other systems.
Advantages of Batch Processing
Batch processing offers several advantages that make it a preferred choice for handling large volumes of data:
- Scalability: Batch processing is highly scalable, making it ideal for organizations dealing with enormous datasets. As data volume grows, batch processing can handle the load efficiently by processing data in manageable chunks.
- Cost-Effectiveness: By processing data in scheduled or periodic batches, organizations can optimize resource utilization, reducing costs associated with real-time processing systems.
- Reduced Complexity: Batch processing systems are often simpler to design, implement, and maintain compared to real-time systems. This simplicity makes it easier to troubleshoot and debug potential issues.
- Fault Tolerance: Batch processing can be made fault-tolerant by implementing mechanisms to handle errors gracefully. If a job fails during processing, it can be rerun without affecting the entire system.
- Consistency: Since batch processing operates on fixed datasets, it ensures consistent results over time. This consistency is essential for tasks like financial reporting or data reconciliation.
Implementing Batch Processing
Now, let us dive into some practical examples of batch-processing implementation using Python and Apache Spark. We’ll explore how to process large CSV files, perform data transformations, and store the results back in a database.
Batch Processing with Python
For this example, we’ll use Python and Pandas, a powerful data manipulation library. We assume that you have Python and Pandas installed on your system.
Python
import pandas as pd
# Function to process each batch
def process_batch(batch_data):
# Perform data transformations here
processed_data = batch_data.apply(lambda x: x * 2) # Example transformation: doubling the values
return processed_data
# Read the CSV file in chunks
chunk_size = 100000 # Adjust the chunk size as per your system’s memory constraints
csv_file = “large_data.csv” # Replace with your CSV file’s path
output_file = “processed_data.csv” # Replace with the desired output file path
# Read the CSV file in batches and process each batch
for chunk in pd.read_csv(csv_file, chunksize=chunk_size):
processed_chunk = process_batch(chunk)
processed_chunk.to_csv(output_file, mode=”a”, header=False, index=False)
In this example, we define a function process_batch() to perform data transformations on each batch. The CSV file is read in chunks using Pandas’ read_csv() function, and each batch is processed using the process_batch() function. The processed data is then appended to an output file.
Batch Processing with Apache Spark
Apache Spark is a distributed computing framework that excels at processing large-scale datasets. It provides built-in support for batch processing. For this example, we’ll use PySpark, the Python API for Apache Spark.
Ensure you have Apache Spark and PySpark installed on your system before proceeding.
Python
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder.appName(“BatchProcessing”).getOrCreate()
# Define the data processing logic as a function
def process_batch(batch_data):
# Perform data transformations here using Spark DataFrame operations
processed_data = batch_data.selectExpr(“col1 * 2 as col1”, “col2 + 10 as col2”) # Example transformations
return processed_data
# Read the CSV file as a Spark DataFrame
csv_file = “hdfs://path/to/large_data.csv” # Replace with your CSV file’s HDFS path
output_dir = “hdfs://path/to/output_dir/” # Replace with the desired output directory path
# Read the CSV file and process each batch
chunk_size = 100000 # Adjust the chunk size as per your cluster’s memory constraints
# Load the CSV data into Spark DataFrame
df = spark.read.format(“csv”).option(“header”, “true”).load(csv_file)
# Process each batch and write back to the storage
df.foreachPartition(lambda batch_data: process_batch(batch_data).write.mode(“append”).csv(output_dir))
In this PySpark example, we create a SparkSession and define the process_batch() function, which performs data transformations using Spark DataFrame operations. The CSV data is read into a Spark DataFrame, and the for each partition method is used to process each partition (batch) in parallel. The processed data is then written back to the storage in CSV format.
Conclusion
Batch processing is a robust technique for handling large volumes of data in scheduled or periodic batches. Its scalability, cost-effectiveness, and simplicity make it an attractive choice for processing vast datasets efficiently. This blog gave us insights into the concept of batch processing, its advantages, and practical implementations using Python and Apache Spark.
By using batch processing effectively, organizations can optimize data processing workflows, gain valuable insights, and make informed decisions that drive business growth and success.