
Data duplication has been a common challenge faced by almost every organization in the modern business day. Wondering why this happens? This can happen because of data entry errors, system migrations, or data integration from multiple sources. Because of this, duplicated data could increase storage costs and slower query performance.
- Data deduplication also known as Data redundancy elimination refers to a process of identifying and removing duplicate data.
- It is required to maintain data accuracy and increase storage.
Here, we will learn few techniques for data deduplication and their impact on reducing storage needs and for improving the query performance.
Types of Data Duplication
Data duplication can be classified into two primary types:
Exact Duplicates: These are identical copies of the same data.
Near Duplicates: These are records that are almost identical but have slight differences.
Common Causes of Data Duplication
Data duplication can occur for several reasons, that also includes::
Data Entry Errors
- Manual data entry can lead to duplicates.
- This occurs when users provide the same information multiple times by mistake.
System Migrations
- Duplicates can be introduced if the process is not taken care of in the right way.
- This happens when data is transferred between two systems
Data Integration from Multiple Sources
- Combining data from two or more sources can lead to duplication.
- This happens when the same information exists more than once.
Impacts of Data Duplication
Duplicated data can have several negative impacts:
- Increased Storage Costs: Duplicate data costs more as it requires more disk storage.
- Slower Query Performance: Query execution takes longer when there are duplicates.
- Compromised Data Integrity: Duplication leads to inconsistencies and inaccuracies making it harder to maintain data quality.
What are Deduplication Techniques?
Prevention vs. Cure
Deduplication can be approached in two ways:
Prevention:
- We can implement measures that prevent duplicates from entering the system in the first place.
- This can be done by setting up rules and checks when the data is entered.
Cure:
- Identify and remove duplicates from the existing data.
- This involves using scripts and tools to automate the deduplication process.
Deduplication Approaches
There are two main methods for deduplication:
Manual Deduplication:
- Manually reviewing data to detect and remove duplicate entries.
- This is time-consuming and not scalable.
Automated Deduplication:
- Using scripts and tools to automatically identify and remove duplicates.
- This is more efficient and scalable.
Data Deduplication Algorithms
Hashing Techniques
- Hashing is a common technique used in deduplication.
- It refers to creating a unique hash value for each piece of data.
- If two pieces of data have the same hash value, they are considered duplicates.
Implementing Hashing in Python
Here is an example of how to use the SHA-256 hashing algorithm in Python to deduplicate files:
python
import hashlib
def hash_file(file_path):
with open(file_path, ‘rb’) as f:
file_hash = hashlib.sha256()
while chunk := f.read(8192):
file_hash.update(chunk)
return file_hash.hexdigest()
file1_hash = hash_file(‘file1.txt’)
file2_hash = hash_file(‘file2.txt’)
if file1_hash == file2_hash:
print(“Files are duplicates”)
else:
print(“Files are not duplicates”)
Checksum Methods
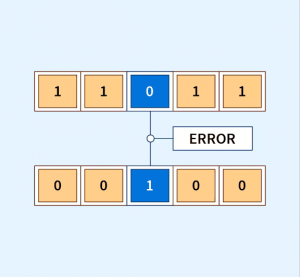
Checksums technique is used for deduplication. It is a small-sized datum derived from a block of digital data to detect errors.
Example Using CRC32 in Python
Here is how you can use the CRC32 checksum algorithm in Python:
python
import zlib
def crc32_checksum(data):
return zlib.crc32(data.encode(‘utf-8’))
data1 = “Hello, World!”
data2 = “Hello, World!”
checksum1 = crc32_checksum(data1)
checksum2 = crc32_checksum(data2)
if checksum1 == checksum2:
print(“Data is the same”)
else:
print(“Data is different”)
What is Deduplication in Databases?
Database Indexing
- Database indexing can help prevent duplicates by enforcing unique constraints on specific columns.
- This ensures that duplicate entries cannot be included in the database.
Example in SQL
Here is an example of how to create a unique index on the email column in a user table:
sql
CREATE UNIQUE INDEX idx_unique_email ON users (email);
What are Normalization Techniques?
- Normalization means organizing the data in the database.
- It helps reduce redundancy.
- It also helps improve data integrity.
- It also helps prevent duplicates.
How does it help prevent duplicates? It makes sure that each piece of data is stored only once.
Here’s an example of how to normalize a denormalized orders table:
sql
— Original Table
CREATE TABLE orders (
order_id INT,
customer_name VARCHAR(255),
customer_email VARCHAR(255),
product_id INT,
product_name VARCHAR(255)
);
— Normalized Tables
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(255),
customer_email VARCHAR(255) UNIQUE
);
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(255)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
product_id INT,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id),
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
What are the Tools used for Data Deduplication?

Open-Source Tools
There are several open-source tools available for data deduplication, such as:
- dedupe.io: A Python library for deduplication and entity resolution.
- Talend Data Preparation: An open-source tool that helps clean and prepare data, including deduplication features.
Commercial Solutions
For larger organizations, commercial solutions may be more suitable due to their advanced features and support.
Some popular commercial deduplication tools include:
Informatica Data Quality: A data quality solution with deduplication features.
IBM InfoSphere: A suite of data integration and quality tools, including deduplication capabilities.
Integration with Data Pipelines
- Deduplication can be integrated into data pipelines.
- This is done to ensure that duplicates are removed as data is ingested.
- Apache NiFi is a powerful tool.
- It can be used for building data pipelines that can include deduplication steps.
Example Using Apache NiFi
Here’s a simple example of how to configure a deduplication processor in Apache NiFi:
xml
<processor name=”DeduplicateFlowFile”>
<property name=”Algorithm” value=”SHA-256″/>
</processor>
Implementation of Deduplication Strategies
Many organizations have successfully employed deduplication strategies to reduce storage costs and improve query performance. Let us take a theoretical example:
Company A: By implementing deduplication, Company A was able to reduce its storage costs by 50% and significantly improve query performance in its data warehouse.
Company B: After migrating to a new system, Company B used deduplication to clean up their data, resulting in more accurate and reliable data for business decision-making.
What are the Best Practices for Data Deduplication?
To achieve the best results with data deduplication, consider the following best practices:
Regular Deduplication Schedules: Perform deduplication regularly to prevent the buildup of duplicates.
Continuous Monitoring and Validation: Monitor data for duplicates continuously and validate the deduplication process to ensure accuracy.
Combining Deduplication with Data Governance Policies: Implement data governance policies that include deduplication as a key component to maintain data quality and integrity.
Conclusion
Data deduplication is essential for reducing storage costs and improving query performance. Understanding the causes and impacts of data duplication helps. It gives clarity on implementing effective deduplication techniques. It also gives a brief idea about using the tools. Adhering to best practices ensures organizations maintain clean, accurate, and efficient data. As data volumes grow, deduplication becomes more integral, making it a key part of contemporary data management.
With these strategies and examples, you’ll be ready to tackle data duplication challenges in your organization.