
In the rapidly evolving field of machine learning, the ability to select the most suitable model for a given problem is crucial. As data scientists, we are often confronted with a vast array of algorithms and models, each promising to offer the best solution. However, the key to successful machine learning lies not just in developing sophisticated models but also in evaluating and selecting the most appropriate ones for our specific tasks.
In this blog, we will delve into the process of model evaluation and selection, exploring various evaluation metrics and techniques to help us identify the best-performing models.
The Importance of Model Evaluation
Before getting into the intricacies of model evaluation, let us understand why it holds such significance in the realm of machine learning.
Model evaluation is the process of quantifying how well a model performs on unseen data. A model that performs exceptionally well on the training data may not necessarily generalize well to new, unseen data. To ensure that we are building robust and accurate models, evaluation becomes paramount.
To get started, let’s consider a classic example of a binary classification problem, where we aim to predict whether an email is spam or not. We’ll use a simple logistic regression model for this demonstration.
python
# Importing necessary libraries
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Generating synthetic data for demonstration purposes
np.random.seed(42)
X = np.random.rand(100, 2)
y = (X[:, 0] + X[:, 1] > 1).astype(int)
# Splitting the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creating and training the logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)
# Making predictions on the test data
y_pred = model.predict(X_test)
# Calculating the accuracy of the model
accuracy = accuracy_score(y_test, y_pred)
print(f”Accuracy: {accuracy:.2f}”)
Common Evaluation Metrics
In machine learning, several evaluation metrics are used to assess the performance of models. Let’s explore some of the most commonly used metrics:
Accuracy
Accuracy is perhaps the most intuitive metric, representing the percentage of correct predictions out of the total predictions made by the model.
python
# Continued from previous code
from sklearn.metrics import accuracy_score
# Calculating the accuracy of the model
accuracy = accuracy_score(y_test, y_pred)
print(f”Accuracy: {accuracy:.2f}”)
Precision, Recall, and F1-score
Precision measures the proportion of true positive predictions out of the total positive predictions. Recall, on the other hand, calculates the proportion of true positive predictions out of the total actual positive instances. F1-score is the harmonic mean of precision and recall, offering a balance between the two metrics.
python
# Continued from previous code
from sklearn.metrics import precision_score, recall_score, f1_score
# Calculating precision, recall, and F1-score
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f”Precision: {precision:.2f}”)
print(f”Recall: {recall:.2f}”)
print(f”F1-score: {f1:.2f}”)
Confusion Matrix
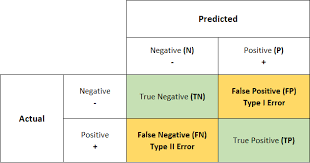
A confusion matrix is a tabular representation that displays the number of true positive, true negative, false positive, and false negative predictions made by a model.
python
# Continued from previous code
from sklearn.metrics import confusion_matrix
# Calculating the confusion matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print(“Confusion Matrix:”)
print(conf_matrix)
Cross-Validation for Robust Evaluation
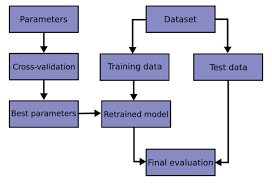
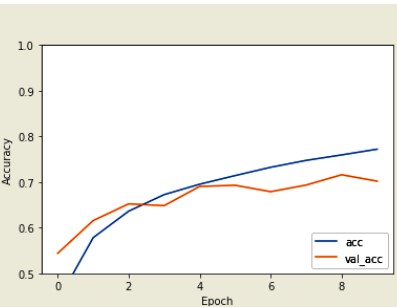
While evaluating a model on a single train-test split gives us some insights into its performance, it is often insufficient to draw definitive conclusions. Variability in the data split may lead to biased evaluations. Cross-validation addresses this issue by performing multiple train-test splits and averaging the results.
python
# Continued from previous code
from sklearn.model_selection import cross_val_score
# Performing cross-validation with 5 folds
cross_val_scores = cross_val_score(model, X, y, cv=5)
mean_cv_accuracy = np.mean(cross_val_scores)
print(f”Mean Cross-Validation Accuracy: {mean_cv_accuracy:.2f}”)
Model Selection Techniques
With a plethora of models available, choosing the best one can be a challenging task. Here are some techniques to aid in model selection:
Grid Search
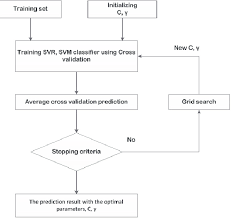
Grid Search is a hyperparameter tuning technique that exhaustively searches through a specified parameter grid, evaluating each combination using cross-validation. It helps identify the best set of hyperparameters for a given model.
python
# Continued from previous code
from sklearn.model_selection import GridSearchCV
# Defining the hyperparameter grid for grid search
param_grid = {
‘C’: [0.1, 1, 10],
‘penalty’: [‘l1’, ‘l2’]
}
# Creating the grid search object
grid_search = GridSearchCV(model, param_grid, cv=5)
# Performing grid search on the data
grid_search.fit(X, y)
# Getting the best parameters and the corresponding accuracy
best_params = grid_search.best_params_
best_accuracy = grid_search.best_score_
print(“Best Hyperparameters:”, best_params)
print(f”Best Accuracy: {best_accuracy:.2f}”)
Randomized Search
Randomized Search is an alternative to Grid Search that randomly samples combinations of hyperparameters from a defined distribution. It can be more efficient than Grid Search when the hyperparameter space is large.
python
# Continued from previous code
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
# Defining the hyperparameter distribution for randomized search
param_dist = {
‘C’: uniform(0.1, 10),
‘penalty’: [‘l1’, ‘l2’]
}
# Creating the randomized search object
random_search = RandomizedSearchCV(model, param_distributions=param_dist, n_iter=10, cv=5)
# Performing randomized search on the data
random_search.fit(X, y)
# Getting the best parameters and the corresponding accuracy
best_params_random = random_search.best_params_
best_accuracy_random = random_search.best_score_
print(“Best Hyperparameters (Randomized):”, best_params_random)
print(f”Best Accuracy (Randomized): {best_accuracy_random:.2f}”)
Conclusion
Model evaluation and selection play a pivotal role in the success of any machine learning project. Evaluating models using appropriate metrics and techniques enables us to identify the best-performing models and build robust, accurate systems. By leveraging techniques like cross-validation, grid search, and randomized search, data scientists can efficiently explore model options and arrive at optimal hyperparameters.
Machine learning is an iterative process, and no single model fits all scenarios. It is essential to understand the nuances of each evaluation metric, the trade-offs between precision and recall, and how to strike a balance to suit the specific use case. Moreover, thoughtful consideration of evaluation techniques can save significant time and resources, leading to the development of models that are better equipped to handle real-world challenges.