Whether it be sophisticated Large Language Models generating texts, images, videos or recommendation systems telling us which movies and TV shows to watch, machine learning is everywhere.
Supervised and unsupervised learning is one of the most fundamental concepts in machine learning. While supervised learning relies on labeled data to train models, unsupervised learning uncovers hidden patterns in unlabeled datasets. In this blog we will explore key differences between supervised and unsupervised learning, their strengths, real-world applications and factors to consider when selecting the right learning.
What Is Supervised Learning ?
In Supervised learning we train an algorithm by spoon feeding it i.e. we supply to it a dataset containing labeled data. In Layman’s terms we supply to the algorithm the question and also the answer. The algorithm is expected to learn the concepts from this data & help answer similar questions later based on the concepts it learnt.
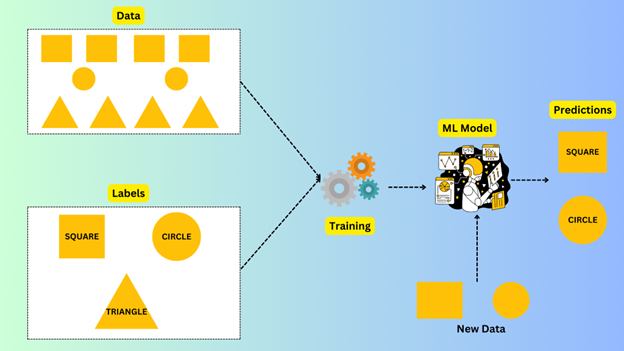
Consider the image below where we supply to the algorithm a dataset of shapes, each labeled whether it is a circle, square or a triangle. We expect it to understand the shapes and learn them. When the model is trained and we then supply it with similar shapes we expect it to predict correctly what shape it is.
Supervised learning is the most popular and we probably interact daily with many systems using supervised learning under the hood for example email classification as spam or not, house price prediction, etc.
Some popular supervised learning algorithms are
- Linear Regression
- Logistic Regression
- Decision Trees
- Support Vector Machines (SVM)
What Is Unsupervised Learning ?
In Unsupervised learning we train an algorithm by not spoon feeding it i.e. we supply to it unlabeled data i.e. there are no questions & answers like in supervised learnings. From this unlabeled data the algorithm is expected to find patterns, groupings and structures within the data
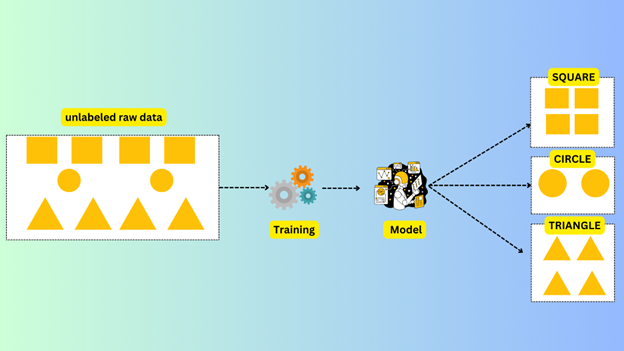
Consider the image below where we supply to the algorithm a dataset of shapes. We expect it to understand the shapes and learn them. When the model is trained it should group similar shapes correctly.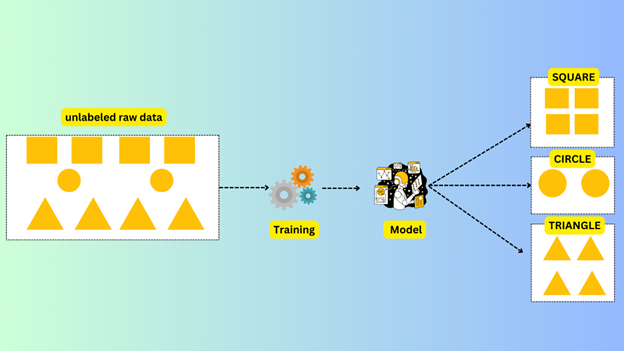
Some popular unsupervised learning algorithms include:
- K-Means Clustering
- Hierarchical Clustering
- Principal Component Analysis (PCA)
- Autoencoders
Key Differences Between Supervised and Unsupervised
Let us now explore the key differences between supervised and unsupervised learning on parameters like data labeling and input, learning process & algorithms and performance evaluation metrics
Data Labeling and Input
Supervised Learning:
Requires labeled datasets where each input is paired with an expected output (target variable). This makes it ideal for tasks like classification or regression, where the goal is to predict specific outcomes based on historical data.
For example, when predicting house prices based on labeled data with features such as size, location, and price.
Unsupervised Learning:
Works with unlabeled datasets, relying on algorithms to infer patterns, clusters, or relationships within the data. This method focuses on data exploration rather than prediction.
For example, Grouping customers into segments based on purchasing behavior without predefined categories.
Learning Process and Algorithms
Supervised Learning:
Follows a structured learning process where the model maps input data to the corresponding outputs.
The model adjusts itself iteratively based on error correction, aiming to minimize prediction errors.
Unsupervised Learning:
Uses data characteristics to identify inherent patterns or structures. Unlike supervised methods, unsupervised learning doesn’t rely on predefined labels, making it exploratory in nature.
Performance Evaluation Metrics
Supervised Learning:
Performance is measured using well-defined metrics, depending on the task:
Classification Tasks: Metrics like accuracy, precision, recall, and F1-score assess the correctness of predictions.
Regression Tasks: Metrics like mean squared error (MSE) and R-squared gauge how close predictions are to actual values.
Unsupervised Learning:
Evaluating performance for unsupervised learning can be more challenging due to the lack of labeled data. Key methods include:
Cluster Validation: Metrics like the silhouette score or Davies-Bouldin index assess the compactness and separation of clusters.
Visualization: Techniques like t-SNE or PCA reduce dimensionality to visually interpret patterns and verify meaningful groupings.
Applications and Use Cases
Now that we understand some fundamental differences between Supervised and unsupervised learning, let us explore some real-world applications of them.
Real-world Applications of Supervised Learning
Image and Object Recognition
Supervised learning powers technologies like facial recognition and medical image analysis. Models are trained to identify objects or abnormalities in images, revolutionizing fields like security and healthcare.
Spam Email Classification
Email filters use supervised learning to distinguish between spam and legitimate emails based on labeled datasets of past email behaviors and content patterns.
Predictive Analytics
Businesses leverage supervised learning for forecasting demand, sales, or financial trends, enabling better decision-making through data-driven predictions.
Stock Price Prediction
By analyzing historical stock data and market trends, supervised models predict future price movements, aiding investors in portfolio management.
Real-world Applications of Unsupervised Learning
Customer Segmentation
Unsupervised learning helps businesses group customers based on purchasing behavior or demographics, enabling targeted marketing campaigns and improved customer experiences.
Market Basket Analysis
Retailers use algorithms like association rule mining to discover product combinations often purchased together, which aids in cross-selling and optimizing product placement.
Anomaly Detection
Unsupervised learning identifies unusual patterns in data, making it valuable in fraud detection, network security, and system monitoring.
Data Compression
Techniques like Principal Component Analysis (PCA) reduce data dimensionality, simplifying complex datasets for easier analysis and storage without losing critical information.
Advantages and Limitations Of Supervised & Unsupervised Learning
Having explored the use cases of both supervised and unsupervised machine learning let us now understand the pros and cons of each of the approaches.
Pros and Cons of Supervised Learning
Some pros of supervised learning are
High Accuracy with Labeled Data
Supervised learning delivers highly accurate predictions and classifications because it learns directly from labeled examples with known outcomes. This makes it reliable for tasks like diagnostics or forecasting.
Applicable to Diverse Tasks
Its flexibility allows application in a wide range of industries, from healthcare to finance, where tasks like risk assessment or customer churn prediction are critical.
Some cons of supervised learning are
Expensive and Time-consuming to Label Data
Preparing labeled datasets requires significant human effort, expertise, and cost, especially for large datasets in fields like medical imaging or video annotation.
Struggles with Large, Unlabeled Datasets
Supervised learning is impractical for massive datasets without labels, limiting its scalability for unstructured or raw data analysis.
Pros and Cons of Unsupervised Learning
Some pros of unsupervised learning are
Requires No Labeled Data
Unsupervised learning can process vast amounts of raw data without the need for expensive labeling, making it ideal for exploratory tasks like clustering or pattern discovery.
Excellent for Exploring Hidden Structures
It reveals insights and relationships in data that might not be immediately apparent, such as customer behavior trends or network anomalies.
Some cons of unsupervised learning are
Results Can Be Harder to Interpret
The lack of predefined labels often leads to ambiguous outcomes, requiring domain expertise to validate the results or derive actionable insights.
Often Less Accurate Than Supervised Methods for Specific Tasks
Since unsupervised learning lacks labeled guidance, it may not perform as well as supervised learning for precise tasks like predictions or classifications.
Choosing the Right Approach for Our Project
Selecting the right machine learning approach between supervised learning and unsupervised learning is key to the success or failure of a project.
Factors to Consider When Selecting a Learning Method
Here are some key factors to guide our decision-making
Nature of the Data
If we have a well-labeled dataset with clearly defined input-output pairs, supervised learning is the go-to approach. For example, predicting loan approval based on customer profiles requires labeled historical data.
If the dataset is unlabeled, unsupervised learning is more suitable. Tasks like clustering customers based on behavior patterns benefit from this approach.
Project Objectives
Identify whether our goal is prediction, classification, or exploring patterns in data.
For tasks such as fraud detection or medical diagnostics, where accurate predictions are crucial, supervised learning is preferred.
If our aim is to segment data or uncover hidden relationships, unsupervised learning is better suited.
Size and Quality of the Dataset
High-quality, labeled datasets suit supervised learning and these models are more prone to success. But creating high quality, well labeled dataset is an expensive and time-consuming task.
Unsupervised learning can handle large, unlabeled datasets, offering flexibility when data labeling isn’t feasible.
Complexity of the Problem
Simple problems with clear relationships between inputs and outputs are well-suited to supervised learning.
Complex problems requiring exploratory analysis, such as discovering unknown customer segments, may benefit from unsupervised methods.
Available Resources
Consider the computational power, time, and expertise at our disposal.
Supervised learning often demands more computation due to the need for extensive training and validation processes.
Real-time vs. Batch Processing
If real-time predictions are required, such as in spam filtering, supervised learning models trained on labeled data can deliver faster results.
For exploratory batch tasks, such as market trend analysis, unsupervised learning works effectively.
Hybrid Approaches: Combining Supervised and Unsupervised Learning
In many real-world scenarios, neither supervised nor unsupervised learning alone can fully help address the problem at hand. In such cases hybrid approaches which combine the strengths of both methods help to deliver more robust solutions which yield better overall results.
Let us now understand a bit more about the hybrid approaches.
Semi-supervised Learning
A technique that uses a small amount of labeled data combined with a large amount of unlabeled data. The labeled data is used to guide the learning process, while the unlabeled data helps in improving the model’s generalization.
For instance, in natural language processing (NLP), annotating every sentence is expensive. Semi-supervised learning can label a small subset of the data and use it to infer patterns in the unlabeled text.
Self-supervised Learning
A subset of supervised learning where the system generates its labels from the input data itself. Models are pre-trained using unsupervised techniques, such as predicting missing parts of data (e.g., masked language modeling in NLP), and later fine-tuned using supervised learning.
This approach powers advanced models like GPT and BERT, enabling them to handle tasks like text classification and question answering efficiently.
Unsupervised Pre-training with Supervised Fine-tuning
Models are initially trained on unlabeled data to learn general patterns, followed by fine-tuning on labeled data for specific tasks.
For example, an autoencoder could learn to compress and reconstruct images in the pre-training phase. The encoder part of this model is then used to initialize a supervised model for image classification.
Frequently used in image recognition tasks where labeled data is limited but abundant unlabeled data is available.
Reinforcement Learning with Unsupervised or Supervised Elements
Combines reinforcement learning’s trial-and-error mechanism with supervised or unsupervised insights. Supervised or unsupervised learning is used to define initial states or policies, which reinforcement learning refines through interaction with the environment.
Robotics applications, where initial clustering of tasks (unsupervised) can speed up policy learning, and supervised fine-tuning ensures accurate task execution.
Multi-task Learning
A hybrid approach where a model learns multiple related tasks simultaneously, sharing knowledge across them. It uses supervised tasks for specific outputs while also leveraging unsupervised tasks to learn general representations.
For example, in speech processing, a model might learn phoneme recognition (supervised) and speaker clustering (unsupervised) together.
Why Use Hybrid Approaches?
Efficiency: Leverages the strengths of both methods to make better use of data.
Cost-Effective: Reduces the need for large amounts of labeled data by integrating unsupervised techniques.
Improved Accuracy: Boosts performance on tasks by combining general pattern recognition with task-specific learning.
Broader Applications: Addresses diverse problem types within the same framework.
In conclusion, the choice between supervised learning and unsupervised learning depends on the problem, the nature of our data, and our project goals. While supervised learning excels in tasks requiring labeled data and precise outcomes, unsupervised learning shines in exploring and understanding unstructured datasets. By understanding their differences, applications, and limitations, we can make informed decisions and leverage the power of machine learning effectively.